Large language models (LLMs) form the basis of natural language processing (NLP) in artificial intelligence (AI). They enable machines to understand, create and communicate with text that resembles text written by humans. They are at the forefront of advancement in the field of artificial intelligence. The demand for highly competent and capable LLMs is constantly increasing as companies in many sectors use AI to drive innovation and improve the customer experience. However, the path to perfecting AI requires constant improvements and optimization. Along the way, pioneering ideas such as Low Rank Adaptation (LoRA) and Quantized Low Rank Adapters (QLoRA) have the potential to transform language model refinement and usher in a new era of AI-powered creativity and language brilliance.
The need for fine-tuning:
Fine-tuning the model is critical to maximizing transfer learning, improving its performance, and tailoring it to specific tasks or domains. Models already built by training on standard datasets may not be able to adequately handle the complexity of the task. Fine-tuning allows the model parameters to be altered to better match the particular requirements of the specific tasks the model is being trained on, thereby improving performance and promoting efficient knowledge transfer.
Departing from conventional fine-tuning methods, we consider two cutting-edge techniques – LoRA and QLoRA – both of which have the potential to redefine the landscape of model optimization and performance improvement.
Introduction to LoRA:
Low Rank Adaptation (LoRA) is a paradigm shift in model fine-tuning for large language models. Traditional techniques, which can be resource-intensive and lead to inefficiency and waste of time and resources, perform fine-tuning of the entire model in the same way, which is unnecessary and undesirable in most cases. In contrast, LoRA distributes the weight matrix into smaller matrices. In this way, LoRA provides a more efficient method and allows targeted updates to specific model components. This reduces memory requirements and improves the efficiency of the fine-tuning process.
Essentially, LoRA helps enterprises precisely and efficiently adapt their Large Language Models (LLMs) to maximize output while minimizing resources. LoRA helps enterprises and organizations achieve more with less effort by carefully balancing resource availability, efficiency, and adaptability through selective updating of model parameters.
Introduction to QLoRA:
Quantized Low-Rank Adaptation (QLoRA), which builds on top of LoRA, further increases efficiency. By using quantization approaches, QLoRA further minimizes memory consumption while maintaining or even improving model performance. QLoRA achieves significant compression over the normal 32-bit format by quantizing the accuracy of the weighting parameters in pre-trained LLMs to a 4-bit format.
This compression not only reduces storage requirements but also improves scalability, making it easier for companies to refine large language models. By combining low-precision storage techniques with high-precision computation techniques, QLoRA opens up a previously unattainable level of efficiency in AI model refinement.
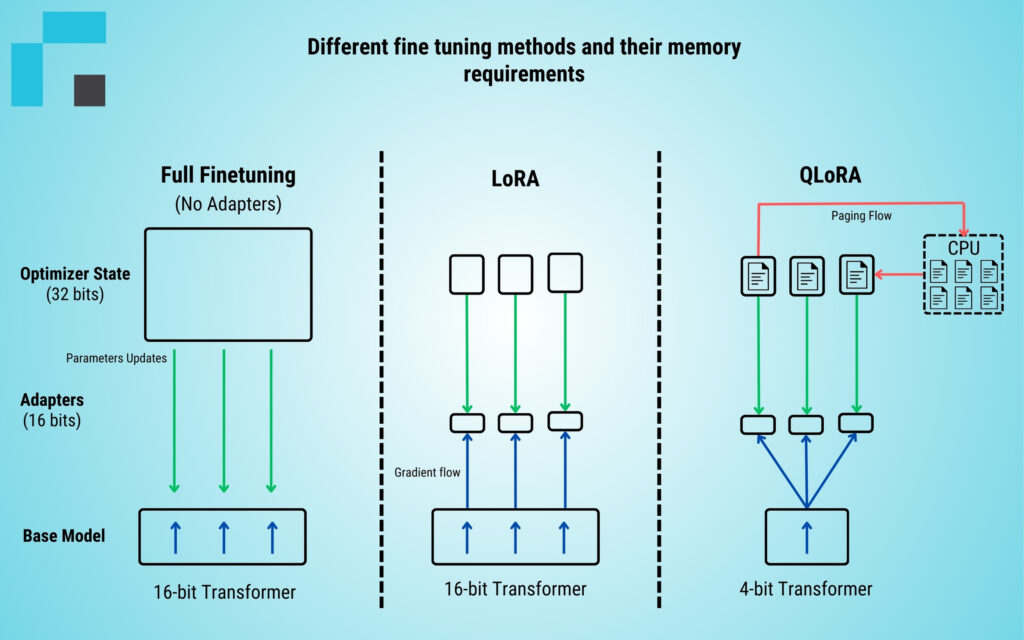
Difference between LoRA and QLoRA:
During the refinement process, LoRA divides the weight update matrix into smaller matrices, allowing targeted updates and focusing on specific model regions. This method maximizes the fine-tuning process while reducing memory and infrastructure requirements. However, QLoRA improves and complements LoRA with additional quantization methods to further minimize memory and resource usage. To achieve this, QLoRA quantizes the accuracy of weight parameters in already trained Large Language Models to a 4-bit format, significantly reducing model size without compromising speed, performance, or efficiency.
Impact on AI innovation:
The integration of LoRA and QLoRA into the fine-tuning process has a profound impact on AI innovation across all industries. By using these cutting-edge technologies, companies can
- Optimize efficiency: Companies can reduce storage and infrastructure requirements by streamlining the fine-tuning process through the use of LoRA and QLoRA. AI-powered products and services will save money and get to market faster as a result of this optimization.
- Scalability: Companies can more successfully develop their AI initiatives thanks to the efficiency benefits offered by LoRA and QLoRA. The ability to maximize resource utilization is critical to long-term success, whether customizing LLM for specific use cases or implementing large-scale AI solutions.
- Competitive advantage: Efficiency is a key differentiator in today’s competitive environment. Companies can outperform their competitors by leveraging modern methodologies such as LoRA and QLoRA, which enable them to deliver creative AI solutions faster and with more flexibility.
- Future-proof: Keeping up with the latest developments in AI requires a forward-looking strategy. Companies can ensure their AI programs remain innovative and future-proof by leveraging emerging technologies such as LoRA and QLoRA.
The inclusion of LoRA and QLoRA in the fine-tuning process is an important milestone in the development of Large Language Models and ushers in a new era of AI innovation. By using these cutting-edge methods, organizations and companies can fully leverage AI to revolutionize the way humans perceive and interact with machines in the future. In an increasingly AI-driven world, LoRA and QLoRA are not only strategically necessary, but also a means to open up new vistas for creativity and opportunity.
Read more here:
AI in logistics: revolutionizing the industry
Advanced AI applications for the insurance domain
Framework for the introduction of Generative AI


