In the fast-moving field of artificial intelligence, model quantization is emerging as a breakthrough strategy to make large neural networks, especially those driving large language models (LLMs), more controllable and efficient. This method involves tuning the accuracy of the models, which directly impacts the size and processing requirements of the model. We have learned from solid experimental evidence that while high precision is critical for certain processes in neural networks, other processes can run just as efficiently with lower precision (e.g. float16), resulting in smaller model size. This allows these scaled-down models to run on less powerful hardware without sacrificing performance or accuracy.
In this blog post we will discuss the core elements of LLM quantization.
What is quantization?
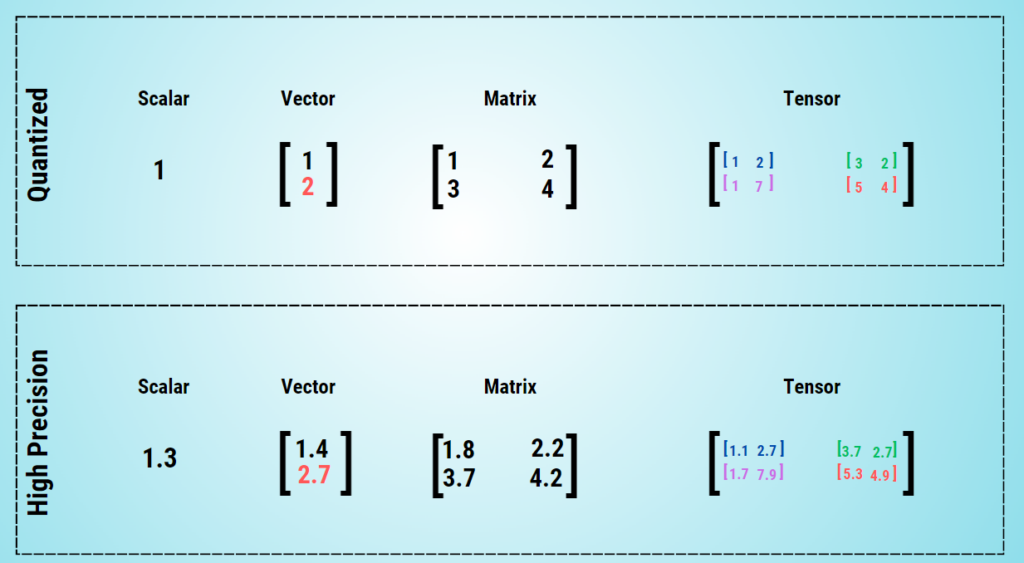
In the context of LLMs, quantization is the process of converting the continuous, infinite values of model weights into a smaller set of discrete, finite values. This is typically achieved by converting weights from higher precision data types (such as Float64) to lower precision types (such as Float16 or even integers). In this context, the term „accuracy“ refers to how much storage space in bits each number takes up in a model. Higher accuracy means higher memory usage and generally higher processing power required.
The role of accuracy in neural networks
LLMs are simply large neural networks that use weights stored as tensors (multidimensional arrays of integers) in GPU or RAM memory. The accuracy of these factors has a direct impact on the memory footprint and processing resources required. Higher accuracy, such as Float64, improves training accuracy and stability, but requires more resources. In contrast, lower accuracy can reduce memory footprint and computational overhead and make operations more efficient.
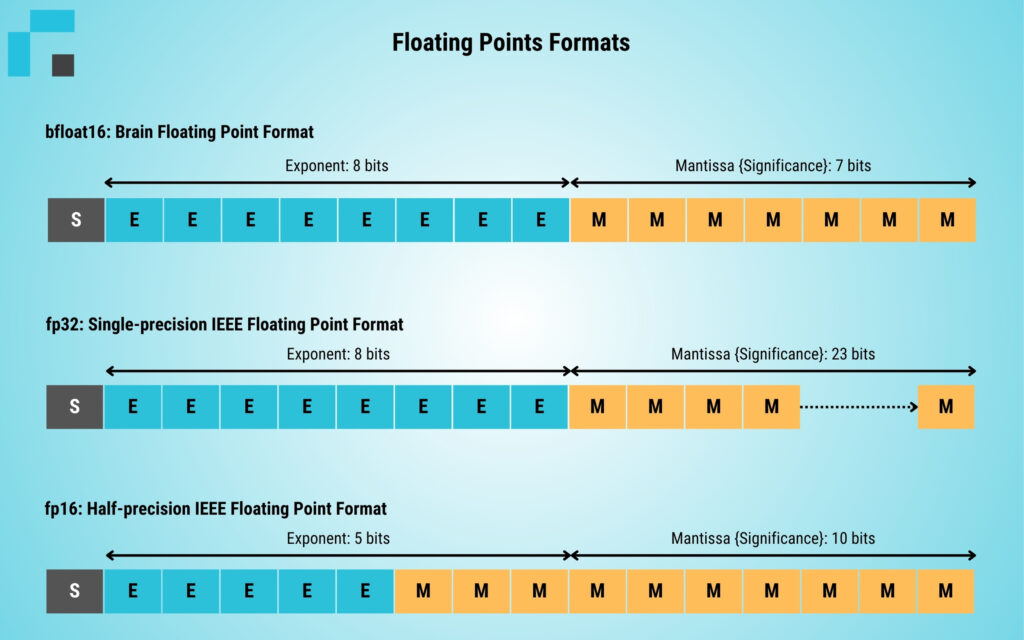
Research from computing giants like Google and Nvidia has proven that lower precision can be used effectively for some neural network functions without drastically reducing performance. Nvidia’s T4 accelerators and Google’s development of the bfloat16 data type are examples of improvements aimed at making lower precision operations more efficient. These developments are critical for deploying large models more cost-effectively and quickly.
Practical implications: A case study on LLM quantization
Take Nvidia’s A100 graphics processor, which offers 80GB of RAM as its top spec. A large model like the Llama2-70B typically requires around 138GB of RAM. Without quantization, hosting this model would require additional A100 GPUs, resulting in higher infrastructure and operational costs. A quantized version of this model, on the other hand, would only require around 40GB, which would fit in a single A100 unit and bring significant cost savings. In addition, the quantized model would execute operations faster in this configuration, increasing performance efficiency.
| Model | Original size (FP16) | Quantized size (INT4) |
| Llama2-7B | 13.5GB | 3.9GB |
| Llama2-13B | 26.1GB | 7.3GB |
| Llama2-70B | 138GB | 40.7GB |
Influence of quantization on model performance
Quantization significantly reduces memory requirements by requiring fewer bits for each weight, allowing models to run on cheaper hardware and at higher speeds. However, this can impact model quality. Larger models retain their efficiency even at lower precision, and some research suggests that 4-bit quantization has little impact on performance.
Types of quantization techniques
Post-Training Quantization (PTQ): This method transforms an already trained model into a model with lower accuracy. It is simpler and faster, but may slightly impact performance.
Quantization-Aware Training (QAT): QAT incorporates the quantization process into the training phase of the model, which often results in better performance but incurs higher computational costs.
Choice between a larger quantified model and a smaller non-quantified model
When optimizing performance and cost, it can be difficult to choose between a smaller, full-fidelity model and a larger, quantified model. However, the results of recent meta-research suggest a nuanced view. However, the results suggest that larger, quantified models can actually outperform smaller, unquantified models under similar inference cost conditions.
This performance advantage is particularly notable for larger models, where the impact of lower accuracy is less detrimental, allowing for better performance, lower latency, and higher throughput. Therefore, for comparable costs, it may be more advantageous to choose a larger quantized model, especially for applications that require large computational resources.
Access to already quantized models from Hugging Face Hub
For those interested in using quantized models, the Hugging Face Hub is a treasure trove. Here you can find various models pre-quantized using different methods such as GPTQ and compatible with frameworks such as ExLLama or NF4. A prominent contributor known on the platform as TheBloke has published a number of models using different quantization techniques, allowing users to choose the best solution for specific applications.
Setting up the environment
To experiment with these quantized models, you can use Google Colab, a free GPU runtime environment. Below are the steps and code to set up your environment:
1 – Install the required libraries: First, make sure you have all the required libraries installed. This includes the Hugging Face Transformer library and additional libraries for the specific quantization method used in the model.
!pip install transformers
!pip install accelerate
# Install libraries for GPTQ quantization method
!pip install optimum
!pip install auto-gptq2 – Restart the runtime: After installation, it may be necessary to restart the runtime in your Google Colab to ensure that all installed packages are loaded correctly.
3 – Loading the quantized model: Once the environment is set up, you can proceed to loading the quantized model. Below is an example of loading a Llama-2-7B chat model quantized using Auto-GPTQ:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Define the model ID from Hugging Face Hub
model_id = "TheBloke/Llama-2-7b-Chat-GPTQ"
# Initialize the tokenizer and model with the specified model ID
tokenizer = AutoTokenizer.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")This code snippet shows you how to prepare your environment and load a pre-quantized model using the special Auto-GPTQ method. By following these steps, you can experiment with quantized models to understand their performance and applicability for different tasks.
Quantizing any model with AutoGPTQ and the transformer library
Although there is a wide range of quantized models available in the Hugging Face Hub, there are scenarios where you need to quantize a model yourself, either because a particular model is not available in quantized form or because you need a model tailored to a specific domain. Below we describe how to manually quantize a model using the AutoGPTQ method from Optimum – a part of Hugging Face for optimizing model training and inference.
Setting up the environment for model quantization
To begin quantization, you need to set up your model and quantization configuration. In this example, we will use a relatively small model to demonstrate the configuration:
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
# Specify the model ID for the base model you wish to quantize
model_id = "facebook/opt-125m"
# Initialize the tokenizer for the model
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Define the quantization configuration
quantization_config = GPTQConfig(bits=4, dataset="c4", tokenizer=tokenizer)
# Load the model with the specified quantization configuration
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=quantization_config)This structure uses 4-bit quantization, which generally represents a good compromise between model size and performance. The dataset „c4“ is used here because of its diversity and size, which are suitable for general language models.
Considerations and potential challenges
Quantizing a model, especially a large model with 175 B parameters, can be very resource intensive and time consuming – often requiring several hours of GPU compute time. Adjusting the number of bits or changing the dataset can significantly affect the performance of the model. To maximize performance after quantization, it is beneficial to choose a dataset that is very similar to the data the model encounters during inference.
Contributing your quantized model to Hugging Face
If you decide to quantize a model, you should share your work with the larger community by publishing it to the Hugging Face Hub:
from huggingface_hub import notebook_login, Repository
# Log in to Hugging Face using your account credentials
notebook_login()
# Create a repository for the model and push it
repo = Repository("opt-125m-gptq-4bit", clone_from="your_username/opt-125m-gptq-4bit")
repo.push_to_hub()Dealing with Performance Degradation
Sometimes quantizing a model, especially with aggressive values or smaller models, can result in performance degradation. When this happens, it can be helpful to adjust the prompts to drive the model more efficiently, which can sometimes help maintain the accuracy and quality of the output.
Notable quantization techniques
Model quantization has evolved with various advanced techniques that improve efficiency and performance. Some important methods are:
- GPTQ: This technique includes variants such as AutoGPTQ and GPTQ-for-LLaMa, which focus on efficient GPU execution.
- NF4: NF4 was implemented using the bitsandbytes library and integrated into the hugging face transformers. It is often used in conjunction with QLoRA methods to refine models to 4-bit precision.
- GGML: GGML is a C library coupled with llama.cpp that supports a unique binary format that speeds up model loading and simplifies access. The recent switch to the GGUF format also improves extensibility and future compatibility.
Each quantization strategy, such as 4-bit, 5-bit, and 8-bit, offers a balance between efficiency and computational power.
Model quantization with GPTQ
The development of GPTQ introduced a groundbreaking approach in the field of model quantization, especially for Generative Pre-Trained Transformers. This method cleverly combines the GPT model line with post-training quantization (PTQ) and adapts the process to efficiently fit large models. The main advantages of GPTQ are described below:
- Scalability: GPTQ is able to compress huge networks, e.g. GPT models with up to 175 billion parameters, with a precision of only 3 or 4 bits per weight. This compression is achieved with a minimal loss of accuracy, and the paper emphasizes that the performance difference between FP16 and GPTQ becomes smaller the larger the model is.
- Performance: With GPTQ, inference tasks for a model with 175 billion parameters can be performed on a single GPU, which represents a significant increase in computational efficiency.
- Inference Speed: On high-end GPUs like the NVIDIA A100, GPTQ can deliver inference speeds up to 3.25x faster than FP16 models. On lower-cost GPUs like the NVIDIA A6000, the speed increase can be up to 4.5x.
GPTQ specifically quantizes models into INT-based data types, most commonly 4INT. When integrated with platforms such as ExLLama, models quantized with 4-bit GPTQ can achieve even higher GPU speedups. Hugging Face’s integration of GPTQ with AutoGTPQ uses ExLLama by default to improve speedups.
ExLLama: Optimized for modern GPUs
ExLLama is a special adaptation of the Llama library for use with 4-bit GPTQ weights. It is designed for high performance and low memory footprint on modern GPUs, making it ideal for newer hardware. The launch of ExLlamaV2 promises further improvements, although it is still in early development.
Practical Application of GPTQ
GPTQ quantization can be applied to a wide range of models and allows conversion to 3-, 4- or 8-bit representations in simple steps. AutoGPTQ, which is characterized by its seamless integration with the Transformer library, remains the most popular tool for implementing GPTQ-related quantization. In the previous sections, a detailed example of using AutoGPTQ for quantization and how to use quantized models effectively was given.
NF4 and double quantization with bitsandbytes for model compression
The NormalFloat (NF) data type, specifically NF4 (4-bit NormalFloat), represents an evolution of the quantile quantization technique. It provides better results than traditional 4-bit integers and floating point numbers. When combined with double quantization (DQ), NF4 achieves higher compression rates without sacrificing performance. The DQ approach consists of two phases: first processing the quantization constants and then using these constants for further quantization to generate FP32 and FP8 values. This method effectively saves storage space – about 0.37 bits per parameter, which is significant for large models such as a 65B parameter model.
The recent addition of these techniques to the bitsandbytes library, as mentioned in the QLoRA paper, has shown that 4-bit quantization can be used effectively in both the inference and training phases for large language models (LLMs) without any performance degradation.
Here’s how to use the bitsandbytes library for NF4 and double quantization, which is seamlessly integrated into the hugging face transformer library:
# Install the bitsandbytes library
!pip install bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
# Configure the NF4 settings with Double Quantization
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
# Specify the model name
model_name = "PY007/TinyLlama-1.1B-step-50K-105b"
# Initialize the tokenizer with the NF4 configuration
tokenizer_nf4 = AutoTokenizer.from_pretrained(model_name, quantization_config=nf4_config)
# Load the model with the NF4 configuration
model_nf4 = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=nf4_config)Please note that quantizing and loading large models can be very resource intensive and requires a lot of RAM, however the example is designed to run on a free Google Colab GPU.
In addition, the bitsandbytes library supports a unique feature that allows model weights to be split between CPU and GPU. The weights on the CPU remain in float32 and are not converted to 8-bit, which can be beneficial when handling large models as it balances the load between GPU and CPU resources. This feature helps in efficiently managing large models without overburdening GPU memory and allows large models to run on more accessible hardware configurations.
GGML and llama.cpp
In the dynamic field of machine learning, GGML occupies a unique position. Named after the initials of its creator Georgi Gerganov, GGML is a C library focused on efficiently processing machine learning tasks. Its uniqueness lies in its proprietary binary format, which was originally developed to distribute LLMs in a way that is different from traditional formats.
Transition to the GGUF format
A major development in GGML evolution is the transition to the GGUF format, which is designed to support a wider range of models than the original Llama-centric format. GGUF is designed to be extensible and future-proof, and to significantly reduce RAM requirements during quantization, making it ideal for a wide range of computing environments.
Integration with the llama.cpp library
The llama.cpp library complements GGML by facilitating the use of LLaMA models, with a focus on 4-bit integer quantization. Its main goal is to enable the use of these models on everyday devices such as MacBooks by optimizing them for low resource consumption while maintaining performance.
Improved functionality for different hardware
Originally, GGML allowed models to be loaded and executed directly on CPUs. However, newer extensions allow certain computational steps to be offloaded to GPUs. This not only speeds up inference, but also enables the execution of large LLMs that would normally exceed the average VRAM capacity.
Consumer hardware with impressive inference performance
Recent developments have shown that a 180B Falcon model can perform inference tasks on a Mac M2 Ultra using GGML and llama.cpp. This is a remarkable demonstration of how quantization can make even the largest models accessible on consumer-grade hardware.
Quantizing an LLM for CPU inference
Quantizing a large language model (LLM) for efficient CPU inference involves several detailed steps. For those interested in applying these techniques, a procedure is suggested here:
- 1 – Read a detailed tutorial that walks you through the GGML and llama.cpp quantization process step by step.
- 2 – Alternatively, a script from the llama.cpp repository can be used to easily quantize any hugging face model.
Final Thoughts on Quantization
Advances in quantization have transformed the use of large language models, making powerful AI capabilities available on everyday devices without sacrificing performance. This democratization of AI technology enables a wider range of users to access advanced language processing tools, encouraging wider adoption and innovation.
The ongoing developments in GGML and llama.cpp are an example of the AI community’s commitment to making cutting-edge technology accessible and usable by a wide range of users. As this field continues to evolve, expect more innovations that will further bridge the gap between cutting-edge AI research and technology available to the general public.


